Like almost everyone else in the tech industry today, I've been looking into LLMs recently. I'm still fairly new to everything but I feel like I'm starting to get a general sense of how things work. What's inside an LLM is something I'm (at least at this point) still considering a black box. Regardless, it's fun to play around with these models and learn more about how they work and how software developers can start using these in their toolkits.
As part of this, I tried to write a simple LangChain program that lets me programmatically work with an LLM running on my machine. The code examples shown on the LangChain documentation default to using OpenAI's ChatGPT, but for whatever reason my OpenAI API keys keep getting rate limited. I didn't feel like shelling out $20 yet, and besides, I have an LLM running locally, so why not make use of it.
Fortunately, LangChain can work with Ollama. The following sections describe the steps I took to get everything working.
1. Install Ollama
The first thing to do is, of course, have an LLM running locally! We'll use Ollama to
do this. On macOS, the easiest way is to use brew install ollama to install Ollama and
brew services to keep it running.
~/W/l/llms main ❯ brew services start ollama
==> Successfully started `ollama` (label: homebrew.mxcl.ollama)At this point Ollama should be listening on port 11434 for incoming requests. You can
open up http://localhost:11434/ in the browser to double check.
Next, browse through the Ollama library and choose which model you want to run
locally. In this case we want to run llama2 so let's ask Ollama to make that happen.
Run ollama pull llama2.
2. Install LangChain
The next step is to have a Python project with all the necessary dependencies installed.
Initialize a Python project somewhere on your machine, using whatever tools you use. I personally use poetry to manage Python projects. The following command should take care of installing all the dependencies.
~/W/l/llms main ❯ poetry add fastapi langchain langserve sse-starlette uvicorn3. Write the code
Now that we have all the dependencies in place, let's focus on the code! Here's the code I used:
from typing import List
from fastapi import FastAPI
from langchain.llms import Ollama
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langserve import add_routes
import uvicorn
llama2 = Ollama(model="llama2")
template = PromptTemplate.from_template("Tell me a joke about {topic}.")
chain = template | llama2 | CommaSeparatedListOutputParser()
app = FastAPI(title="LangChain", version="1.0", description="The first server ever!")
add_routes(app, chain, path="/chain")
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=9001)As you can see, there are a few things going on in this code. We first build an Ollama
model object with the model set to llama2. Next we write a simple prompt template with a
parameter called topic. We'll later see how the user can pass a topic to get back a
response from the LLM. Next, we initialize a chain using the LangChain Expression
Language. Finally, we initialize a new FastAPI application and then use
langserve.add_routes to mount the LangServe API routes.
Save this code to a file called main.py and run it using python main.py. This should
start a FastAPI server containing the LangServe endpoint we just defined. On my machine
I see the following message when the app starts:
~/W/l/llms main ❯ python chain.py
INFO: Started server process [25442]
INFO: Waiting for application startup.
__ ___ .__ __. _______ _______. _______ .______ ____ ____ _______
| | / \ | \ | | / _____| / || ____|| _ \ \ \ / / | ____|
| | / ^ \ | \| | | | __ | (----`| |__ | |_) | \ \/ / | |__
| | / /_\ \ | . ` | | | |_ | \ \ | __| | / \ / | __|
| `----./ _____ \ | |\ | | |__| | .----) | | |____ | |\ \----. \ / | |____
|_______/__/ \__\ |__| \__| \______| |_______/ |_______|| _| `._____| \__/ |_______|
LANGSERVE: Playground for chain "/chain/" is live at:
LANGSERVE: │
LANGSERVE: └──> /chain/playground/
LANGSERVE:
LANGSERVE: See all available routes at /docs/
LANGSERVE: ⚠️ Using pydantic 2.5.1. OpenAPI docs for invoke, batch, stream, stream_log endpoints will not be generated. API endpoints and playground should work as expected. If you need to see the docs, you can downgrade to pydantic 1. For example, `pip install pydantic==1.10.13`. See https://github.com/tiangolo/fastapi/issues/10360 for details.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:9001 (Press CTRL+C to quit)And that should be it! You can now visit http://localhost:9001/chain/playground/ to
play around with the LLM interface you just built! Here's a screenshot of the LangServe
Playground I see on my machine:
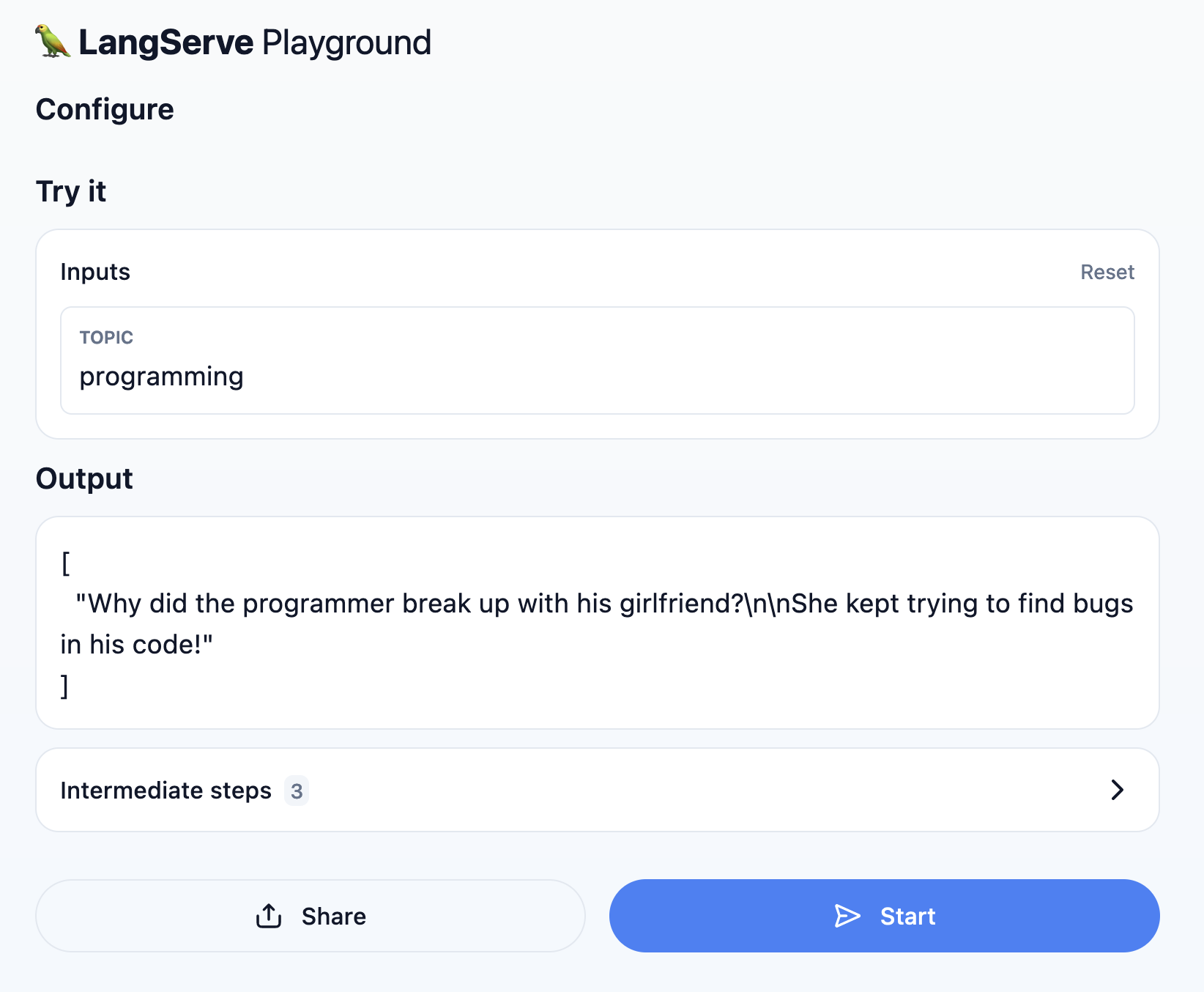
It works! And the cool thing is that there are no API keys or anything involved. All the code necessary for this application is running locally.